
As it’s my turn to write weeknotes, I’m going to try my best to explain how the data team are making content analysis algorithms which analyse video and audio in near real time. Previously I explained how we’re having to re-write the algorithms themselves to work in a different way; today I’m going to explain how we get the audio and video to those algorithms. This is quite specialist, but could be extremely useful for someone who encounters this problem in the future. If that's not you then you could skip to the end and read about the rest of the team.

The answer is: - Gstreamer is complex (probably necessarily so), and there are very few on showing how to do this in our language of choice (python).
Setup: You need a recent version of Gstreamer, at least 1.14. On Ubuntu this means compiling from source. And remember, when compiling gst-python, set --with-libpython-dir otherwise gstreamer will silently fail to find your plugins
Path: Put your plugin in a folder called python and set the GSTPLUGINPATH to the directory above the folder called python.Once you’ve done that, all that remains is to write a class which implements your plugin.
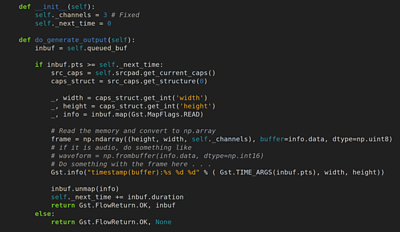
Here is a skeleton which we’ve used in our projects. The idea is to write a plugin which converts the gstreamer buffer into something we’re familiar with, a array. Once it’s in that format we can use all sorts of .
First, import the required libraries:

Next, we create our class, extending GstBase.BaseTransform.
This class needs some fields to be defined. The most important one is gsttemplates which define the data format which the pads accept. In our case we want raw video frames in BGR format.
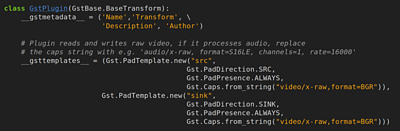
Finally, outside of the class, register the plugin so that gstreamer knows about it

To use the plugin in Gstreamer, make sure that gstreamer can find it:
export GSTPLUGINPATH=$PWD
And call the plugin like this - we’re constructing a pipeline consisting of an element which plays a file (or stream), converts the video, our plugin, and a sink (which does nothing with the data):
gst-launch-1.0 uridecodebin uri=file:///test.mp4 ! videoconvert ! gstplugin_py ! fakesink
Of course, once you’ve got the data into python, you can analyse it in many different ways, for example: trying to detect faces (as in the screenshot above) in the video, or transcribing the speech from the audio.
Here's what is going on in the rest of IRFS:
Over in the discovery team, Tim, David and Jakub have continued working on the project with ���˿��� Four. They have been finalising the designs, working on ‘visual energy’ analysis and producing several demos to present to ���˿���4.
Chris has been working on Quote Attribution project and completed a Keras-based disambiguator for Mango.
Kristine has demoed her ���˿��� radio station themed Introducing playlists to ���˿��� Sounds.
In the Experiences team: Joanne and Joanna have been evaluating the outputs of the Cars workshop held in the last sprint with members of IRFS, Newslabs and others. Libby has been wrapping up the Better Radio Experiences work and preparing a blog post to be published soon.
News have started testing their latest prototypes with under-26s in London, developing the prototypes further, and have published a blogpost and describing what came our of the first phase of this project from the Autumn last year. They are looking forward to a pilot of one of our first prototypes which should be published very soon.
Chris built an MPEG-DASH based demo, to test whether browser implementations support Remote Playback API in combination with Media Source Extensions.
He also gave a presentation to the News Labs team on why and how to go about open sourcing their work. The British Library are using our code as part of their project, so Chris has been helping them get started.
Links
- (using Gstreamer, in python)
Search by Tag:
- Tagged with Weeknotes Weeknotes